Multimodal Learning
- Audio, Video, Image, Text 등 다중 형태의 데이터를 모델의 입력으로 사용
- 단일 형태 데이터(모달)의 한계를 극복하고자 여러 형태의 데이터를 사용해 주어진 문제를 해결하는 모델을 구축
- 왜 멀티모달이 필요할까? → 인간이 멀티모달이니까 (맥거크 효과)
https://www.youtube.com/watch?v=PWGeUztTkRA
multimodal deep learing
- 각 모달에 적합한 딥러닝 구조를 사용해 특징 추출

- 모달 통합 방식으로는 대표적으로 Feature concatenation, Ensemble classifier 두 가지 방법이 존재
- (a) ex. 이미지는 CNN, 텍스트는 RNN을 사용해 피쳐 벡터를 추출해 결합해 사용하는 방법
- (b) ex. 이미지 모델에서 나온 분류 결과와 텍스트 모델에서 나온 분류 결과의 ensemble 결과를 이용하는 방법
예시
- 차량 사고에 큰 영향을 주는 운전자의 스트레스 수준 분석 및 감지
- Input : ECG 데이터 + 차량 데이터(패달 밟기, 휠 전환 등) + 환경 데이터(다음 차량과의 거리, 차선, 차선간 넓이, 날씨, 시간 등)
- 인간의 감정 인식 모델 성능 향상
- Input : 음성, 영상(음성이 제거된) 데이터
- process : 입력 데이터를 segment 별로 분리
→ 음성의 경우 2D CNN을 사용하고 영상의 경우 3D CNN 사용
→ Fusion network(segment 마다 추출된 오디오, 비디오 특징 벡터 병합 후 average-pooling)를 통해 합쳐줌
Core Challenge
Representation : 표상
- 서로 다른 Modality 입력을 하나의 벡터 공간에 투상
- 공간상 가까운 위치에 유사한 개념이 모이도록 함

Translation : 번역
- 한 양식에서 다른 양식으로 데이터를 변환

Alignment : 정렬
- Modality들 간의 상관관계 파악

Fusion : 융합
- 서로 다른 형태의 데이터는 서로 다른 속도로 일반화 됨.
- 데이터 간 Fusion을 통해 모델 성능/정확도를 높이는 것

Co-Learning : 함께 학습
- 한 Modality에서 학습된 지식을 다른 Modality로 전이/확장
- ex. 말하는 사람의 얼굴 비디오와 음성 데이터가 함께 있다면 → 음성 인식 신경망에서 더 나은 lip-reading 모델을 만들 수 있음
CLIP
Contrastive Language-Image Pretraining model


Contrastive pre-training
- 사전 교육된 이미지 인코더와 텍스트 인코더를 이용해 데이터 세트의 어떤 텍스트와 어떤 이미지가 쌍을 이루는지 예측
- 대각선에 위치한 것이 정답일 때 이들의 코사인 유사도를 최대화하고 나머지 쌍들의 코사인 유사도를 최소화 하는 방향으로 이미지 인코더, 텍스트 인코더를 학습시킴
- 이미지 인코더로 ViT(Vision Transformer), ResNet 두가지 버전이 있음
- 텍스트 인코더로는 Transformer 사용
zero-shot prediction
- 모델이 학습 과정에서 배우지 않은 작업을 수행하는 것
- ex. 학습 과정에서 존재하지 않았던 종류의 이미지의 결과를 유추
- plane, car, dog 등 단어들을 label로 지정하고 ‘A photo of a {label}’ 문장으로 만듦
→ 이를 토큰화 함
→ 텍스트 인코딩 벡터 생성 / 이미지 인코딩 벡터 생성
→ 한 이미지와 라벨의 정보가 담긴 텍스트 인코딩 사이 코사인 유사도를 구함
→ 가장 유사도가 큰 값을 라벨로 반환
GLIP
Grounded Language-Image Pre-training
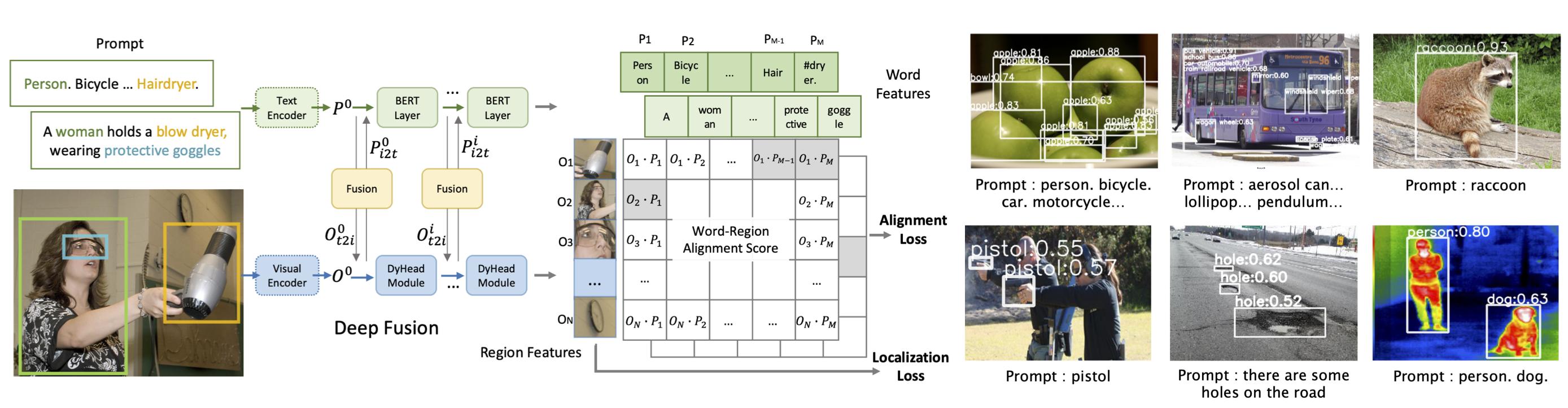
- 텍스트는 단어 단위 임베딩, 이미지는 object 단위 임베딩 후 각각에 맞는 모델로 훈련 (중간에 Fusion network)
- 텍스트 모델은 BERT
- 이미지 모델은 Dynamic Head
- 이미지에서 물체를 감지해 해당 물체의 명칭(텍스트)이 함께 나타남
BLIP
Bootstrapping Language-Image Pre-training
- Image Encoder, Text Encoder, Image-grounded Text encoder, Image-grounded Text decoder 4가지가 사용됨.
- 이미지 모델 : visual transformer (ViT)
- 텍스트 모델 : BERT
- Image Captioning, Visual Dialog 가능
Image Captioning

Visual Dialog

728x90
'데이터 어쩌구 > 기술 써보기' 카테고리의 다른 글
| [NLP] Negative Log Likelihood (0) | 2023.08.28 |
|---|---|
| 훈련시 활용한 자원 및 툴 (0) | 2023.08.28 |
| [Class 101] 협업 필터링 기반 추천 목록 만들기 (0) | 2023.08.27 |
| [Class 101] 룰 베이스 기반 추천 목록 만들기 (0) | 2023.08.27 |
| [Class 101] 추천시스템 이해하기 (0) | 2023.08.27 |