- Meta 2023 AI at Meta, 2023년 기술 회고
GitHub - facebookresearch/ImageBind: ImageBind One Embedding Space to Bind Them All
초록
- 6가지 모달리티에 대해서 임베딩을 join 할 수 있는 모델
- 이미지, 텍스트, 오디오, 깊이, thermal, IMU data
- IMU : inertial measurement unit
- 물체가 기울어진 각도를 측정하기 위한 관성 측정 장치
- IMU : inertial measurement unit
- 이미지, 텍스트, 오디오, 깊이, thermal, IMU data
- 오로지 이미지와 연결된 데이터만 있다면 (6가지 다 없어도) 훈련할 수 있는 모델
1. 서론
- 하나의 이미지를 볼 때 우리는 많은 경험과 연결지어 생각할 수 있다.
- 예컨대 해변을 볼 때, 파도의 소리 / 모래의 감촉 / 산들 바람 / 시를 부르는 영감을 얻을 수도 있겠다.
- 이상적으로는 이 모든 센서들을 동일한 임베딩 공간에 놓는다면 좋겠지만, 실현하기는 어렵다...
- 이미지와 텍스트 / 이미지와 음성 등을 align 하는 방법론들이 많이 나오고 있다.
- 그러나 이 방법들의 경우 훈련 모델에 한정한 모달리티만 동일 차원으로 변환시킴. 그래서 비디오-오디오 임베딩은 이미지-텍스트 테스크와 바로 연결하여 사용 불가.
- 각기 다른 차원의 임베딩 연결의 가장 큰 장애는 대량의 멀티모달 데이터의 부재이다.
- IMAGEBIND
- 이미지 - 다른 모달리티의 조합을 훈련하여 같은 차원 내에 있도록 함 representation space
- 암시적으로 정렬하여 (명시적 의미 텍스트 페어링 없이도) 제로샷 인식이 가능
- IMAGEBIND는 적은 훈련으로 다양한 양식과 작업에 적용할 수 있음
- IMAGEBIND의 공동 임베딩이 할 수 있는 것
- 교차 모드 검색
- 산술을 통한 임베딩 결합
- 이미지에서 오디오 소스 감지 및 오디오 입력이 주어진 이미지 생성 등

2. 관련 연구
1) Language Image Pre-training
2) Multi-Modal Learning
- 본 모델과 가장 유사한 훈련 방식 Nagrani et al. (Attention Bottlenecks for Multimodal Fusion)
- 일반적으로 다양한 모달리티를 효과적으로 결합하기 위한 방식으로 최종 표현이나 예측을 결합.
- 하지만 해당 모델은 여러 계층에서 정보를 결합하기 위해 attention bottlenecks(주의 병목현상)을 사용한다. 간단한 데이터로 부터 강력한 검색 기능을 만들 수 있는 방법
- AudioCLIP
3) Feature Alignment (Self-supervision)
- Point-CLIP : 사전 훈련된 CLIP 인코딩 된 2D → 3D로 정렬
- 다국어 신경 기계 번역 : 학습된 implicit bridge를 통해 동일한 잠재 공간에서 언어를 학습하면 쌍을 이루는 데이터가 제공되지 않은 언어로 번역될 수 있는 기술.
3. 방법
- 각각의 모달리티에 이미지만을 연결한 데이터 pair를 이용해서 훈련
3-1) Preliminaries (예선)
- 여러 모달리티의 구체화된 조합 정렬
- Contrastive learning (image-text , audio-text , image-depth , video-audio 등)
- 각각의 pair로 훈련된 경우, 같은 차원에 있지 않음
- Zero-shot image classification using text prompt : 텍스트 프롬프트를 이용한 이미지 분류 제로샷
- 각 클래스 사진에 대해 다양한 텍스트를 대응시켜 한 번도 보지 못한 대상(class)에 대해 예측하게 하는 것.
- 해당 방법처럼 Zero-shot을 이용하기 위해서는 (audio-text , point cloud-text) 와 같은 설명 가능한 text 데이터쌍으로 훈련해야함.
- 이미지바인드는 text 아닌 다른 모달리티에서도 제로샷 분류를 할 수 있다.
3-2) Binding modalities with images
- 의미론적 개념을 지닌 거대 스케일 웹 데이터셋을 기반으로 함
- 추가로, 자연적으로 생성된 다른 모달리티의 쌍(모달리티-이미지)도 함께 훈련
- Loss : InfoNCE
- I : Image, M : 다른 모달리티
- 같은 것끼리는 가깝게, 다른 것 끼리는 멀게 훈련.
- τ : softmax의 결과가 한쪽으로 극적으로 치우치게 하거나 또는 그것을 방지하기 위한 temperature


- Emergent alignment of unseen pairs of modalities (사용되지 않은 다른 모달리티와의 정렬)
- 훈련되지 않은 조합의 모달리티 (M1, M2)도 (I, M1), (I, M2)의 조합으로 훈련 없이 검색작업이 가능하다.
3-3) Implementation Details
- Encoding modalities : 모든 모달리티 인코더에 대해서 Transformer을 사용함
- Image, Video → ViT (Vision Transformer) : 2초 단위 샘플에서 2개의 프레임 사용
- Audio → 2초 단위 샘플에서 16kHz 128 mel-spectrogram bin를 사용해 스펙토그램으로 변환
- 이것도 이미지와 같은 2차원 신호이므로 Patch size가 16이고 stride 10인 ViT 사용
- Depth → 1채널의 이미지로 보고 ViT를 사용해 인코딩.
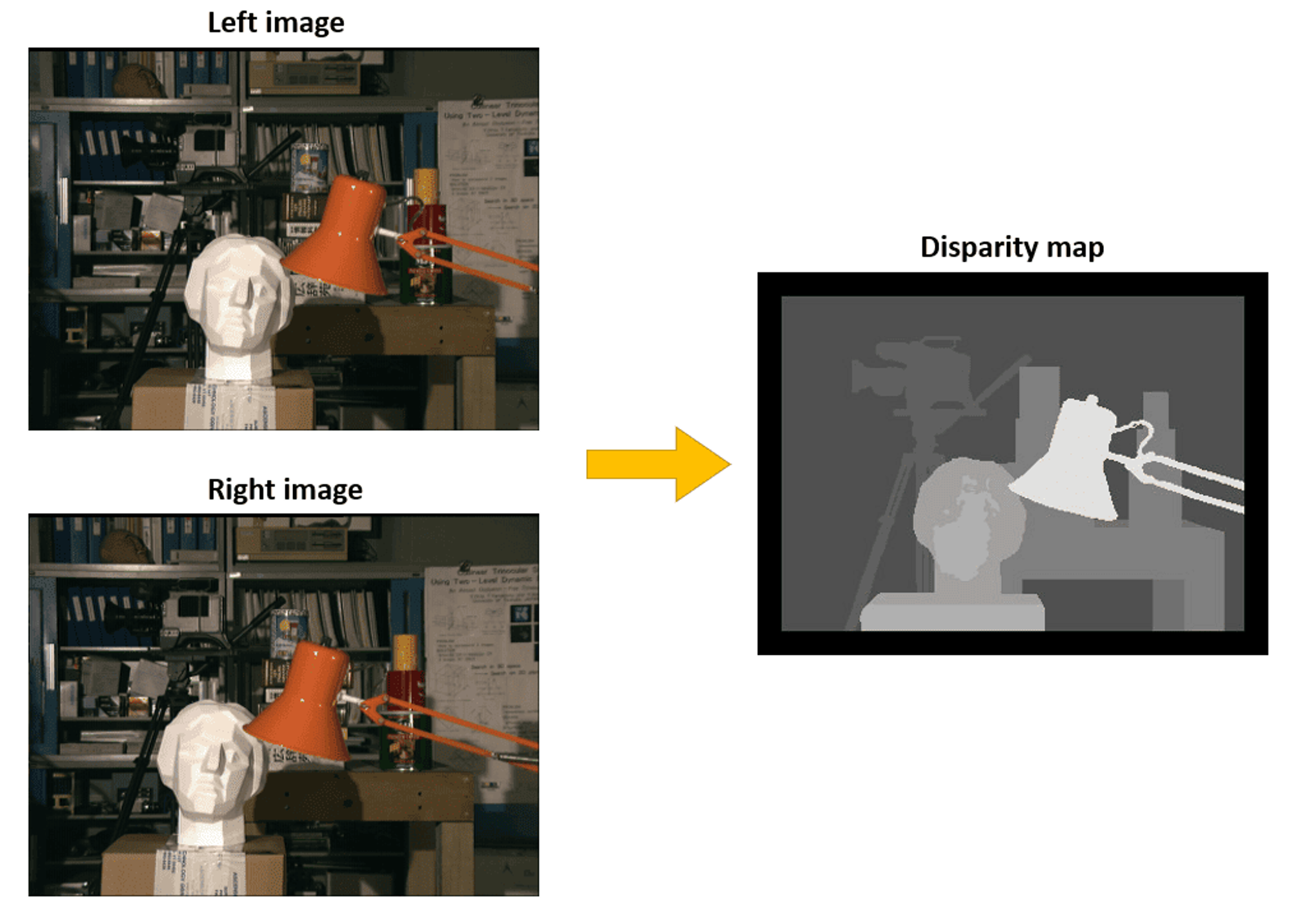
- 스케일 불변성을 위해 깊이를 disparity map으로 변환.https://www.baeldung.com/cs/disparity-map-stereo-vision
- IMU : 물체가 기울어진 각도를 측정하기 위한 관성 측정 장치
- X, Y, Z 축에 걸친 가속도계와 자이로스코프(각속도계) 측정으로 구성된 IMU 신호를 추출
- 5초 클립을 사용하여 커널 크기가 8인 1D convolution을 사용하여 project되는 2천 timestep IMU 판독값을 생성
- 결과 시퀀스는 Transformer를 사용하여 인코딩. 마지막은 CLIP의 텍스트 인코더 디자인을 따름
- 모든 모달리티에 InfoNCE loss를 적용하기 위해 동일 차원으로 정규화 해야 함. 그래서 각 인코더에 모달리티별 linear projection head를 head에 붙임.
- 이 설정을 사용하면 사전 학습된 모델(clip, open-clip) 인코더의 부분 집합을 초기화 할 수 있다.
4. 실험
- emergent zero-shot 오디오 분류, 텍스트 분류 등 (생략) : SOTA에 비해 낮은 정확도
Analysis and Applications
- 이미지 임베딩과 오디오 임베딩을 더한 후 이미지를 검색

- 오디오 쿼리를 이용해 Object detection

- 오디오 기반으로 하는 이미지 생성 Diffusion Model

5. Ablation study
인과관계 파악을 위한 연구 (일반적으로 모델이나 알고리즘의 feature들을 제거하며 그 행위가 성능에 얼마나 영향을 미치는지 확인)
5-1) 이미지 인코더 스케일링
- 이 모델은 이미지 표현의 역할이 가장 큰 모델로 ViT 사이즈를 바꿔가며 실험해봄.
- 이미지 인코더, 모달리티 별 zero-shot 결과 비교
- 이미지 인코더의 사이즈가 클 수록 연결(binding)이 잘 되는 것으로 보임

6. 논쟁 및 한계
- 이미지바인딩은 이미지 정렬만을 활용해 동일 임베딩 공간에 투영하는 간단하고 실제적인 방법이다.
- 우리의 방법은 모든 모달리티를 관통하는 측정/평가 evaluate이 가능하다. 다른 다중 모달리티의 모델을 개선(upgrade)하는데도 도움을 준다. (이미지-텍스트 모델을 오디오로 개선 등)
- 이미지 바인딩 한계 및 개선점
- 전문 모델보다 성능이 뒤떨어짐
- 해당 모델을 평가할 수 있는 지표 (벤치마크) 필요
- 프로토타입이라 실제 앱에 활용하기 어려움
728x90
'데이터 어쩌구 > 기술 써보기' 카테고리의 다른 글
| 이미지 생성 모델 (2024. 02) (0) | 2024.02.27 |
|---|---|
| [기록] OCR 변환한 한글을 DB 내 가까운 결과로 반환하기 (0) | 2023.12.07 |
| XAI (eXplainable AI) 개념 요약 (0) | 2023.09.08 |
| TensorFlow Lite를 이용한 기기 내 대규모 언어모델 탑재 실습 (0) | 2023.09.03 |
| [Paper] CLIP : Learning Transferable Visual Models From Natural Language Supervision (2021) (0) | 2023.09.03 |


